RetailSMV: Multi-View Video Dataset for Retail World Models
Teaching foundation video world models the physical reality of retail — and answering which camera viewpoint actually carries the adaptation signal.
RetailSMV is the first retail video corpus with synchronized egocentric and exocentric capture of real store-staff operations at foundation-model fine-tuning scale — and the first controlled study showing that exocentric-only adaptation matches or beats combined ego+exo training with half the data.
Need access to the full 32K synchronized corpus? Contact Sales

Base vs. RetailSMV-adapted video world model. The same retail prompts are continued by pretrained Cosmos3-Nano (top, red) and by our RetailSMV-adapted LoRA (bottom, green) under identical inference settings. Adaptation preserves scene layout, action grounding, and physical geometry where the pretrained baseline drifts.
The Problem We're Solving
Foundation video models are pitched as world simulators for embodied agents. But they are pretrained on internet-scale generic video — entertainment, vlogs, dashcam footage — not the dense shelving, narrow aisles, and multi-person dynamics of a real supermarket.
Without adaptation, generated retail scenes drift toward generic interiors within seconds: fridge doors pass through bodies, hands penetrate crates, and aisle walls open onto sections that don't exist. RetailSMV closes that gap — and shows exactly which training viewpoint closes it best.
Key Stats
Three View-Stratified Configurations
Three matched LoRA configurations of Cosmos3-Nano (16B DiT, rank 32, α=64, 3,000 steps), trained under identical hyperparameters and optimization budget — isolating training-data viewpoint as the only variable.
Egocentric-Only · n=16,120
Head-mounted camera worn by store staff. Specializes in first-person motion patterns and hand–object interaction, at the cost of wide-field scene structure.
Exocentric-Only · n=15,985 — The Winner
Fixed scene camera observing the same activity third-person. Specializes in scene layout, multi-actor dynamics, and wide field of view.
Combined Ego + Exo · n=32,105
The natural default of using all available data — plus a second seed to bound seed variance. Never significantly beats exocentric-only on any metric.
Qualitative Examples
Ground truth (top row) vs. base, egocentric-only, exocentric-only, and combined configurations extending the same conditioning frame over seven seconds. Red cells mark the base model's most visible failure.

Hand-off watermelon. Base drifts away from the multi-person produce display and ends in the wrong section of the store. All three adapted configurations preserve the produce context and a two-handed grip consistent with the prompt.

Opening a fridge to pick a vegetable. Base produces a geometry-violating frame at t=5 s in which the fridge door passes through the person's body. The adapted configurations preserve open-door geometry and a plausible reach.
Four Things RetailSMV Proves
Domain adaptation succeeds uniformly
All three LoRA configurations cut validation diffusion loss ~2.8× (1.006 → 0.355–0.363), with every one of 200 paired samples improving over the pretrained base at p ≪ 0.001. Seed variance is four times smaller than configuration spread.
Half the data, from the right viewpoint, wins
Exocentric-only adaptation matches or exceeds combined training on six of seven point estimates and is significantly better on LPIPS (p<10⁻⁷), PSNR (p=0.003), and DreamSim (p<10⁻⁹) — despite training on 15,985 clips versus 32,105. In-distribution viewpoint coverage beats raw clip count.
Data contribution is asymmetric
Adding exocentric data to egocentric-only training helps significantly (LPIPS, PSNR, SSIM at p ≤ 0.0018). Adding egocentric data to exocentric-only training hurts significantly (LPIPS, PSNR, DreamSim at p ≤ 0.003). The exocentric subset carries the adaptation signal.
The gap lives in the near-horizon window
The LPIPS gap to the base is largest at the shortest rollout time (t=0.5 s: 0.542 vs. 0.460) and remains substantial through 1–2 s — exactly the window embodied planning and policy verification rely on. At t=1.0 s, exo-only reaches +0.075 paired LPIPS gain at 89% win-rate (p<10⁻²⁸).
Main Results — 200-Clip Held-Out Test Set
| Configuration | LPIPS ↓ | PSNR ↑ | SSIM ↑ | CLIPScore ↑ | DreamSim ↓ | R3D-Fr. ↓ | JEDi ↓ |
|---|---|---|---|---|---|---|---|
| Pretrained base | 0.668 | 10.68 | 0.215 | 0.815 | 0.263 | 42.69 | 1.246 |
| Egocentric-only | 0.626 | 11.01 | 0.226 | 0.832 | 0.220 | 37.65 | 0.960 |
| Exocentric-only | 0.610 | 11.26 | 0.235 | 0.834 | 0.201 | 35.14 | 0.829 |
| Combined ego+exo | 0.619 | 11.18 | 0.236 | 0.832 | 0.216 | 36.20 | 0.892 |
Best value per column in orange. Exocentric-only wins six of seven; combined edges it on SSIM only, by 0.0012 — a difference that is not statistically distinguishable. Every metric reported with paired t-test and Wilcoxon signed-rank p-values in the paper.
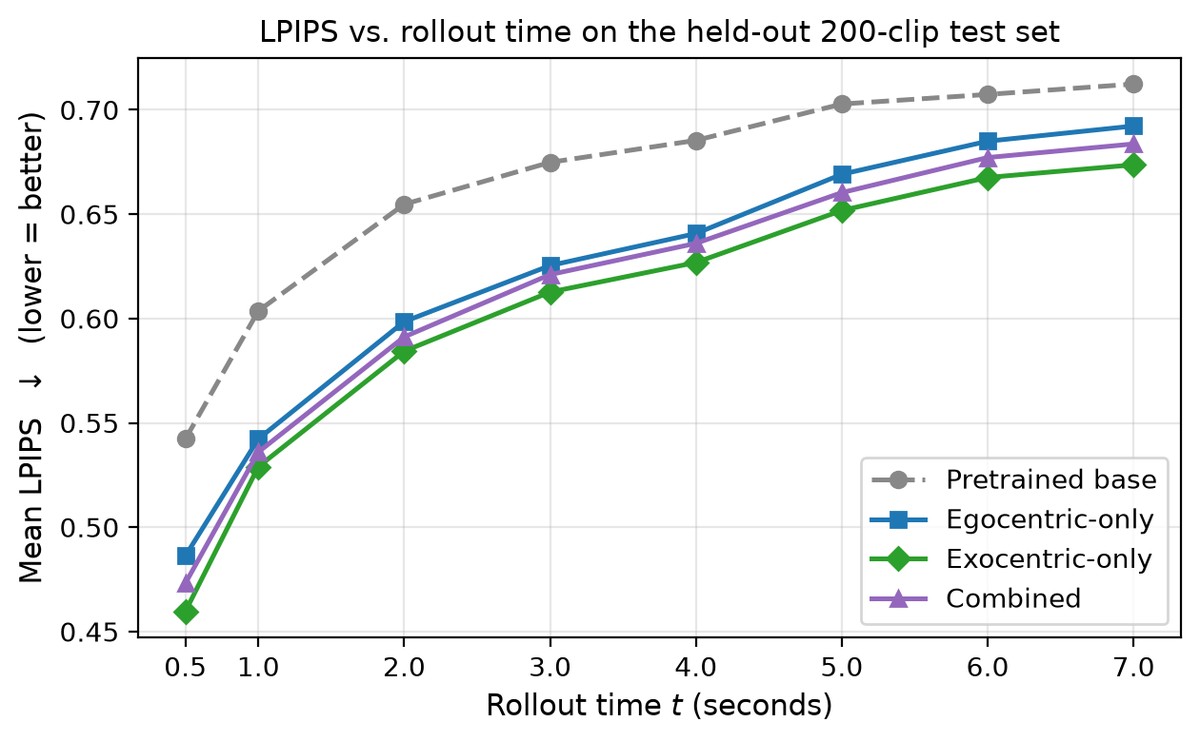
LPIPS vs. rollout time. The gap to the pretrained base is widest at the shortest rollout time (t=0.5 s) and narrows as t grows — concentrating the adaptation benefit in the near-horizon window that embodied planning relies on. Exocentric-only (green) leads at every timestamp.
What's Inside
32,105 clips of real store-staff operational work
Stocking, arranging, weighing and labelling produce, carrying crates, pushing supply carts, scanning at checkout, assisting customers — clips of 1–8 s. Every ego clip has a synchronized exo clip of the identical activity at the same wall-clock time.
Dense paragraph-level captions on every clip
Store and section, high-level task and low-level action, hand states and body pose, visible products and signage, and a frame-by-frame motion summary — ready as text conditioning for any text-and-image-to-video model.
Pre-defined train / validation / test
Train: 32,105 clips (16,120 ego / 15,985 exo). Validation: 1,388 clips for adapter selection. Test: 200 stratified clips (100 ego / 100 exo), disjoint by unique identifier. All faces de-identified at source in both views and all splits.
A reproducible statistical standard
Seven complementary metrics — LPIPS, PSNR, SSIM, Hessel CLIPScore, DreamSim, R3D-Fréchet, JEDi — computed with wall-clock time-aligned sampling, reported with mean paired difference, win-rate, and both parametric and non-parametric p-values.
RetailSMV is a research release from DreamVu — a Physical AI data infrastructure company building the data foundation for the next generation of embodied robots. RetailSMV complements PRISM, our vision-language dataset: PRISM targets embodied vision-language supervision, while RetailSMV is organized for video-world-model adaptation with paired ego/exo clips, generation captions, adaptation splits, and generated-video evaluation protocols. Our multi-view capture infrastructure is available for organizations building physical AI systems for retail, logistics, healthcare, and industrial environments.